Predicting the NBA Finals with R
This is the initial post about the algorithm. See updates [1](http://viksalgorithms.blogspot.com/2012/06/predicting-nba-playoff-games- results.html), [2](http://viksalgorithms.blogspot.com/2012/06/nba-playoff- predictions-update-2-and.html), and [3](http://viksalgorithms.blogspot.com/2012/06/nba-playoff-predictions- update-3-4-2.html) for more. The algorithm is currently 4-2 in the playoffs!
Overview
I was struck by Martin O’Leary’s recent post on predicting the [Eurovision finals](http://mewo2.github.com/nerdery/2012/05/20/ive-got-eurosong-fever- ted/), which led me to decide that I would try to predict NBA games using mathematical models. As the finals are ongoing, this is a quite timely decision! You can read through everything or scroll to the end for finals predictions and accuracy results.
This model is necessarily very different (read: nothing in common at all) from Martin’s, because the underlying concept that we are predicting, and how it is derived, are very different. The outcome of NBA games are determined by a variety of factors, such as the scoring ability of each team, whether the teams are playing at home or away, and whether or not any players are injured. It stands to reason that several of these factors can be modeled, and used to predict whether a team will win or lose a given game. But, we are getting ahead of ourselves. The first step, as always, is to acquire the data.
Getting the Data
Game data is actually quite difficult to get in machine readable form. This is likely because while there is a major demand for data that can be casually read and looked over, there isn’t a major public demand for sports data feeds. As I lacked enough of a budget to become an ESPN “partner”, I had to resort to more utilitarian methods, which gave me data in essentially a “box score” format. This format gave the statistics for each team for each game.
Reformatting the Box Scores
The majority of the problem at this point is actually reformatting the data to make it into a useful form for analysis. A box score is good, but if we want to predict who will win a game in the future, it isn’t very useful. The problem is in getting from something like the table below to something that an algorithm can read in:
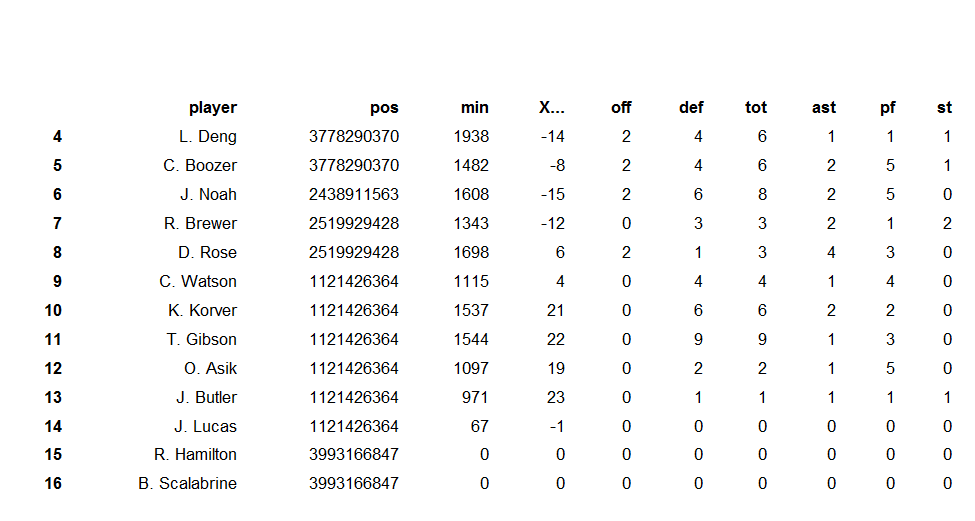 As always, this is where the not so glamorous side of data analysis comes in; it takes a lot of time to convert data into a useful form.
As always, this is where the not so glamorous side of data analysis comes in; it takes a lot of time to convert data into a useful form.
Computing Summary Statistics
I first computed summary statistics for each team for each game, such as rebounds per game, blocks per game, etc:
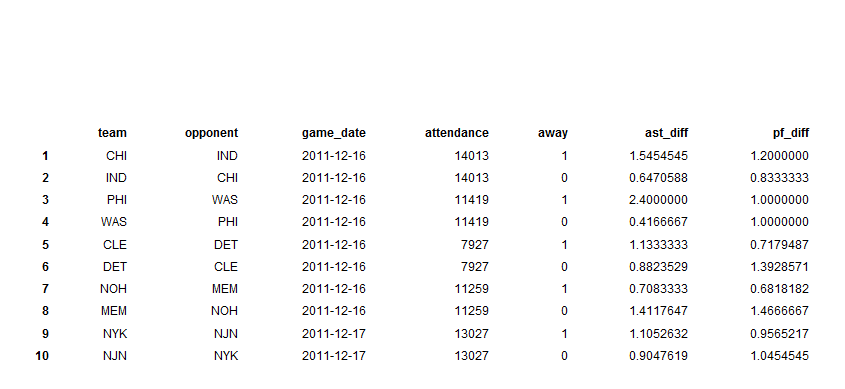 This is truncated, and a lot of variables are left out, but it gives you an idea of how it came about. Basically, I summarized the box scores and converted them into “observations”, where each teams performance becomes one row. I computed indicators such as rebounds per player, turnovers per player, etc.
This is truncated, and a lot of variables are left out, but it gives you an idea of how it came about. Basically, I summarized the box scores and converted them into “observations”, where each teams performance becomes one row. I computed indicators such as rebounds per player, turnovers per player, etc.
The next problem with this is that there is very little predictive ability in just the previous game’s statistics. In order to predict future games, we need to know a teams performance for the whole season. At this point, I split the data up by team, and treated the season for each team as a time series. This allowed me to compute summary statistics for the whole season, and for the last 10 games for each team. We could see the rebounds per game, for example, for the whole season.
Here is how the data looked at this point:
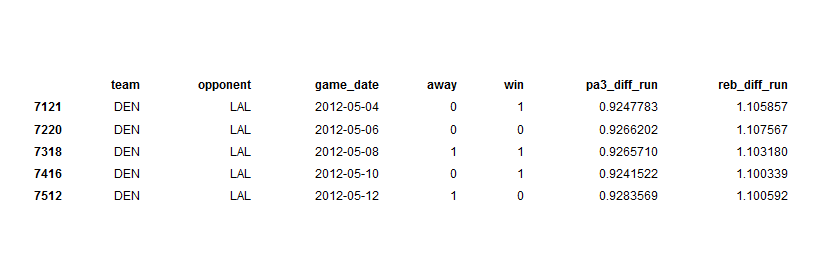 Note that this is truncated in terms of both rows and columns. Essentially, for each game, the running statistics for the team up to that point are available.
Note that this is truncated in terms of both rows and columns. Essentially, for each game, the running statistics for the team up to that point are available.
For example, here are Denver’s season running averages for assists, points, and rebounds:
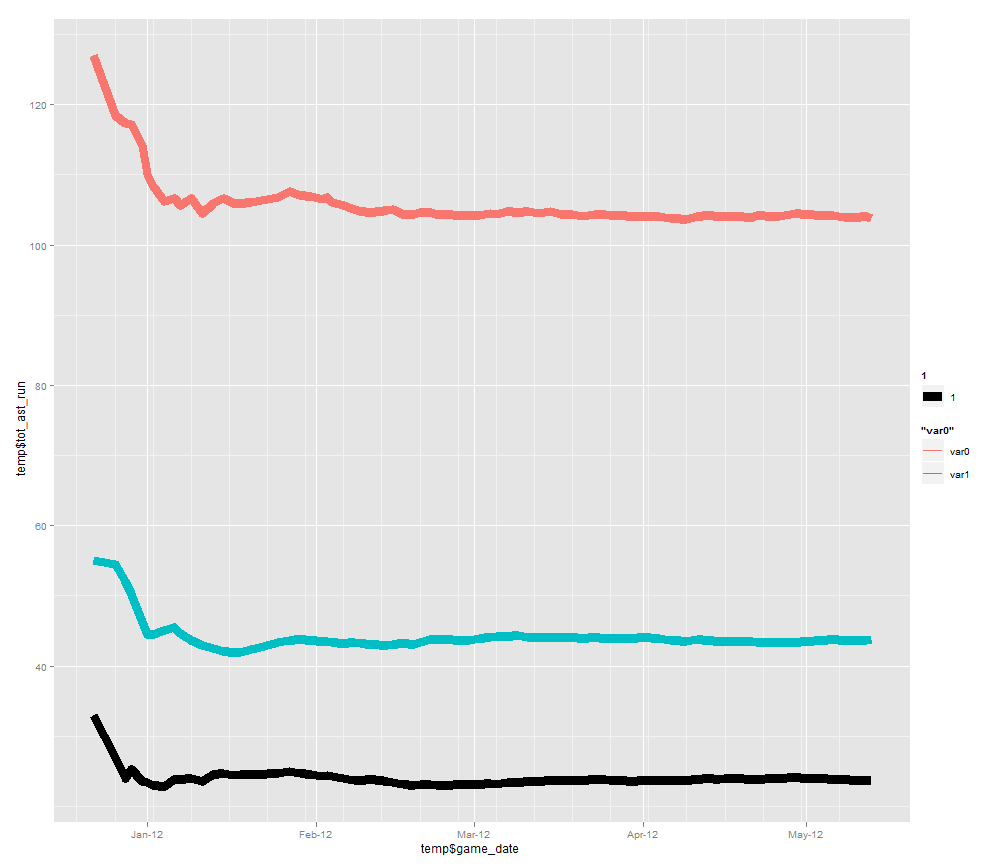 And here are Denver’s 10 day back averages:
And here are Denver’s 10 day back averages:
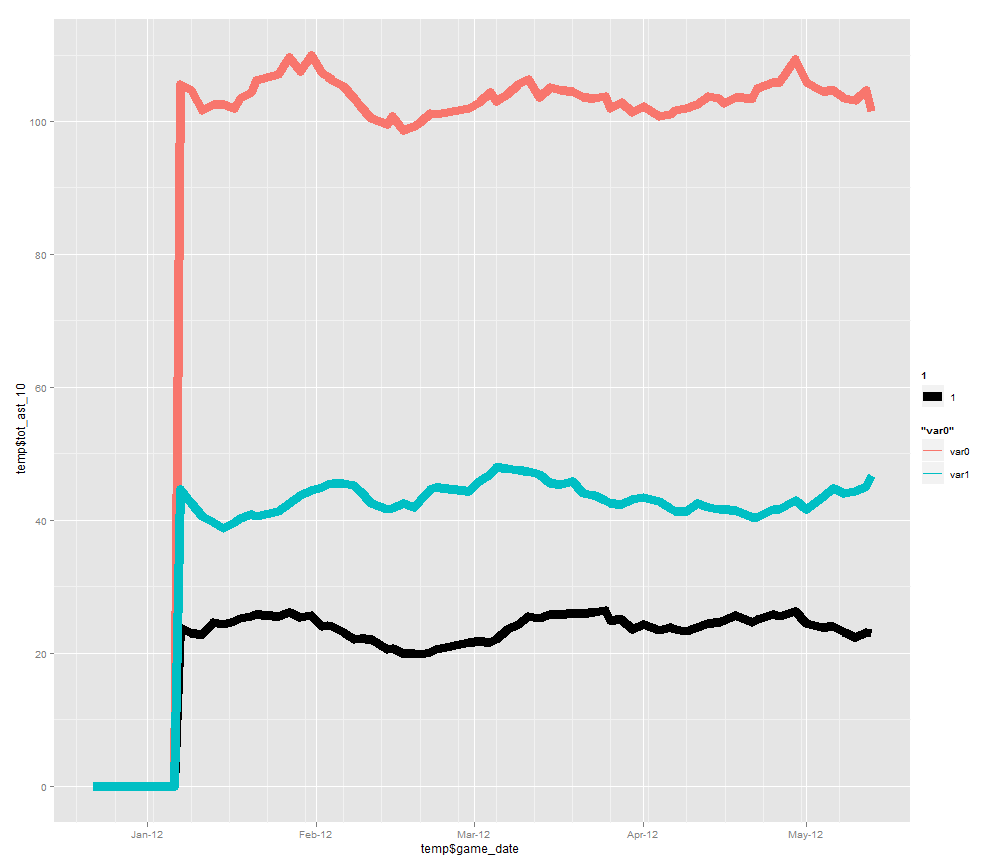 As you can see, there are some interesting patterns in the 10 day back statistics that do not appear in the season running averages. This is why it is useful to have both, and to take the ratio between the two.
As you can see, there are some interesting patterns in the 10 day back statistics that do not appear in the season running averages. This is why it is useful to have both, and to take the ratio between the two.
Putting all the data together
The next step was to put together the statistics for each team for each game with the similar statistics for their opponent. Once this was accomplished, the result could be fed into predictive algorithms. This left me with a table where each row contained data for a team, and for its opponent, in terms of their season performance.
Finally, Some Machine Learning
I was finally able to put all of the data together, and predict game winners based on this. I used all of the games for the season (minus 10 games for each team at the beginning needed to initialize the 10 period means), and used cross validation to predict results. This causes some issues because it has future data to predict “past” data, but should still be relatively accurate.
For the actual machine learning framework, I used a simple combination of three different classification algorithms (they were combined via their median). The predictions were made as 1 (the team won), or 0 (the team lost).
This resulted in the following table:
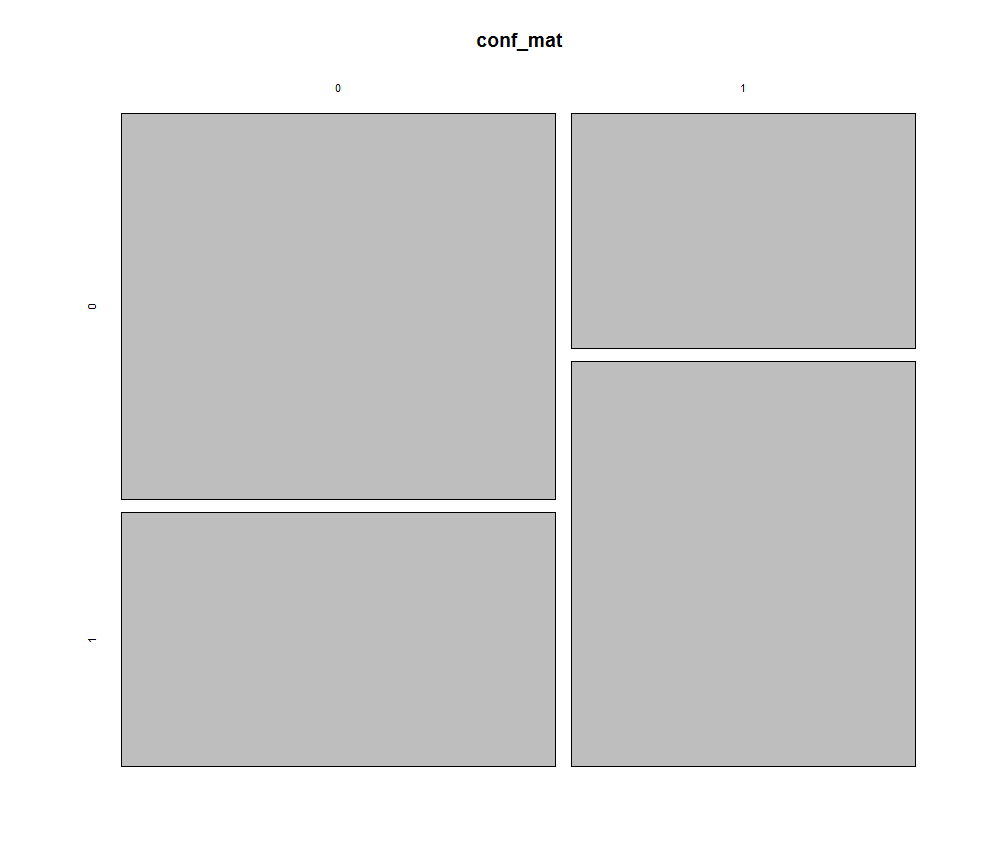 The x-axis is predicted result, and the y axis is the actual result. As you can see, the predicted result matches the actual result in the majority of the cases.
The x-axis is predicted result, and the y axis is the actual result. As you can see, the predicted result matches the actual result in the majority of the cases.
To be specific, the algorithm correctly predicted 1323 winners/losers, and incorrectly predicted 823 winners/losers over the whole season. This gives it a 61.5% prediction accuracy for the season, which is pretty good for a days work!
Now, if we feed in data for the first 2/3rds of the season, and we predict the final 1/3 of the season, we get the following matrix:
 This is pretty similar to the cross validated error, and the prediction accuracy comes to about 60.5%.
This is pretty similar to the cross validated error, and the prediction accuracy comes to about 60.5%.
The accuracy is likely lower than it should be simply because the predictions are being made for 1 month or more at a time. If predictions were restricted to one day/game ahead, accuracy would be much improved.
Potential Improvements
Of course, this is a very rough system, and both the data and the methods can use a lot of refinement. 61% is a good lower bound for accuracy, but with some work, it could go up significantly. The main improvements that could be made are in the data acquisition, in the variable calculation, and in the final models that are used to calculate the win/loss.
The system can also be modified to predict points or point spreads, which might make things a bit better as well.
And of Course, Predictions for the Finals!
And, last but not least, I will leave you with some NBA finals predictions. I am currently predicting one day/game ahead for the finals, but I might work on altering this to predict further in advance if needed.
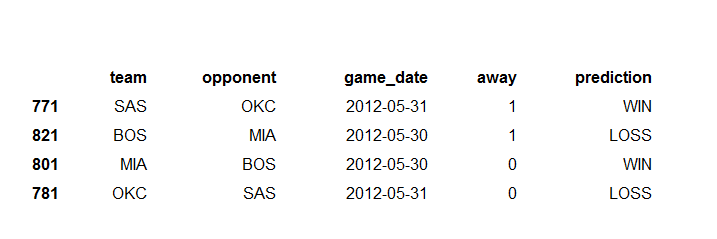 So, here it is predicting that both Miami and San Antonio will win their next game. This seems strange in practice, but we will see how it plays out!
So, here it is predicting that both Miami and San Antonio will win their next game. This seems strange in practice, but we will see how it plays out!
