Tracking US Sentiments Over Time In Wikileaks
Introduction
I [recently posted](http://viksalgorithms.blogspot.com/2012/06/finding-word- use-patterns-in-wikileaks.html) about using the Wikileaks cable corpus to find word use patterns, both over time, and in secret cables vs unclassified cables.
I received a lot of good suggestions for further topics to pursue with the corpus, and probably the most interesting was the idea to do sentiment analysis over time on a variety of named entities.
Sentiment analysis is the process of discovering whether a writer feels negatively or positively about a topic. Named entities in this case would be country names such as China and India, and the names of important world figures, such as Saddam Hussein or Tony Blair.
So, in essence, we are seeing how US diplomats, and by extension the US, felt about a variety of topics, and how those feelings changed over time, from the first available cables (1980’s) to present.
The goal is to get a chart like this one:
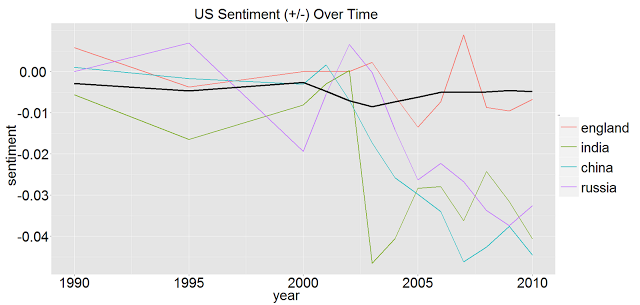 How will we do this?
How will we do this?
Useful sentiment analysiscan be extremely complex at times, requiring a corpus of sentences to be mapped to sentiment scores.
In order to make this exercise simpler, I traded off some accuracy and used a word list instead (the AFINNlist). This word list assigns a “sentiment score” of -5 to 5 to 2477 English words. For example, the word adore has a score of 3, denoting a positive sentiment, whereas the word abhorred has a sentiment of -3, indicating negative sentiment.
Our next task is [named entity recognition](http://en.wikipedia.org/wiki /Named-entity_recognition). We will use the AFINN word list in conjunction with a list of named entities. Named entities in this case would be important topics from the news, so we will use the [JRC-Names](http://langtech.jrc.it /JRC-Names.html) word list, which pulls out important keywords from news articles. We will use these keywords to define our topics. For example, “China” is a keyword, as is “India”. These are the topics that we will analyze sentiment for.
Now, in order to find the sentiment for a given topic, we will need to find out whether it appears in conjunction with negative or positive words. For example, the phrase “China abandoned an environmental project” would indicate negative sentiment, whereas “China is building partnerships” would indicate positive sentiment. In order to do this, we will need to find out when our topic words (named entities) and our words that indicate sentiment appear together in a sentence.
To accomplish this, we can use a technique called random indexingwhich allows us to build up a matrix that shows how topic words and sentiment words occur together. I opted to use random indexing because it builds a relatively small matrix in terms of dimensionality, and it allows us to capture information on a fairly granular level. The optimal method would be to create a full Term-Document matrix and decompose it to find relations, but it is impractical in this case due to the high sentence count.
Our plan
Now that we have all the prelimiaries, here is a high-level look at what we will do:
- Get cables for multiple time periods from the database * Because there are more cables from 2000 onwards than from pre-2000, we will define 5 year time periods from 1985 to 2000, and 1 year time periods after.
- Split the cables into sentences.
- Build up matrices using random indexing that contain the topic words from JRC-Names and the sentiment words from AFINN.
- Use cosine similarity measures to see how often topic words occur with negative/positive words.
- Assign a final “sentiment score” to each topic for each time range.
This plan will give us reasonable results. Because of the way that we are doing sentiment analysis, it won’t be perfect (far from it), but it will show some interesting patterns, at least.
Formatting JRC-Names and AFINN
JRC-Names and AFINN are not in the best format for this (you will see when you download them), so we need to reformat them to get a character vector of topics. The reformatting also needs to be done because cables frequently refer to people by only their last name and JRC-names contains a full name. We need to make everything into 1-grams.
jrc_names <- read.delim(file = "entities.txt", stringsAsFactors = FALSE)[,
4]
bad_names <- grep("[^\w+]", jrc_names, perl = TRUE)
jrc_names <- jrc_names[-bad_names]
jrc_names <- sapply(jrc_names, function(x) strsplit(x, "+", fixed = TRUE))
jrc_tab <- sort(table(tolower(unlist(jrc_names))), decreasing = TRUE)
jrc_names <- names(jrc_tab)[jrc_tab > 2]
jrc_names <- jrc_names[nchar(jrc_names) < 15 & nchar(jrc_names) >
2]
afinn_list <- read.delim(file = "AFINN-111.txt", header = FALSE,
stringsAsFactors = FALSE)
names(afinn_list) <- c("word", "score")
afinn_list$word <- tolower(afinn_list$word)
full_term_list <- c(jrc_names, afinn_list$word)
This code will remove non-English words from jrc-names, split it by the + sign that appears in each term, and reconstruct a vector in which only the terms that appear at least twice are included.
Defining Date Ranges
We now need to define what date ranges we want our cables to come from. Because there aren’t many cables available pre-2000, we will select 5 years at a time from 1985-2000.
date_min_list <- c("1985", "1990", "1995", "2000", "2001", "2002",
"2003", "2004", "2005", "2006", "2007", "2008", "2009")
date_max_list <- c("1990", "1995", "2000", "2001", "2002", "2003",
"2004", "2005", "2006", "2007", "2008", "2009", "2010")
Generating Sentiment Scores
Now, we need to follow our plan from above and have the code that generates our final sentiment scores. The load or install function is documented [here](http://viksalgorithms.blogspot.com/2012/05/loading-andor-installing- packages.html).
This code is very inefficient, so please feel free to improve it. To get it to run on low-memory systems, you can lower the ri_cols or max_cables_to_sample attributes. A higher ri_cols or max_cables_to_sample setting will be less memory efficient, but more accurate.
You can find the code for this here, as sentiment_score_generation.R.
This is a very long piece of code, but it is basically doing what our plan stated. It is getting cables for each time period, splitting them into sentences, and finding out which sentiment words and topic words occur together. It is then finding out which topic is associated with negative sentiment, and which is associated with positive sentiment, and then assigning a final score to each topic on that basis.
Plotting the results
Now, we are ready to make plots indicating sentiment over time.
You can find the plotting code here, as sentiment_plot.R.
This generates the following plot:
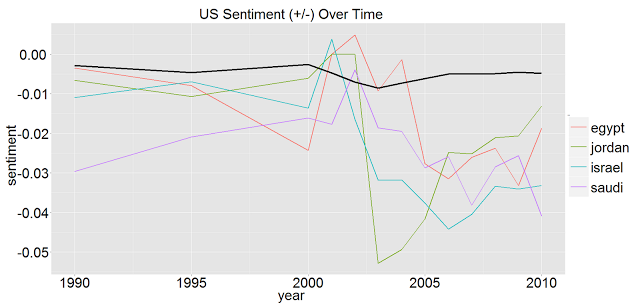 The black line indicates the mean sentiment by year. You can see that the average US sentiment dips around 2003 (the year on the x-axis is the ending year for the gathered cables, so 2010 would be cables from January 1st, 2009 to January 1st, 2010, for example). This is likely due to countries not supporting the US war effort in Iraq. If you have a better interpretation, I would love to hear it.
The black line indicates the mean sentiment by year. You can see that the average US sentiment dips around 2003 (the year on the x-axis is the ending year for the gathered cables, so 2010 would be cables from January 1st, 2009 to January 1st, 2010, for example). This is likely due to countries not supporting the US war effort in Iraq. If you have a better interpretation, I would love to hear it.
More country plots
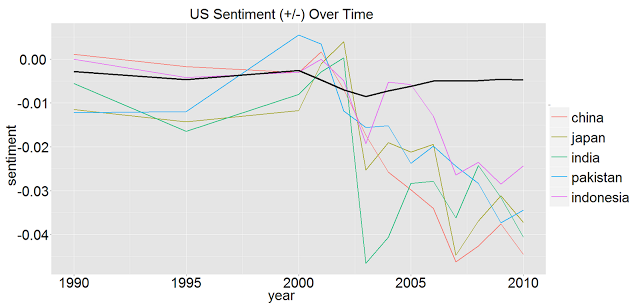
Here are US sentiments towards the english speaking world. “New Zealand” becomes “Zealand” because we are only dealing with 1-grams:
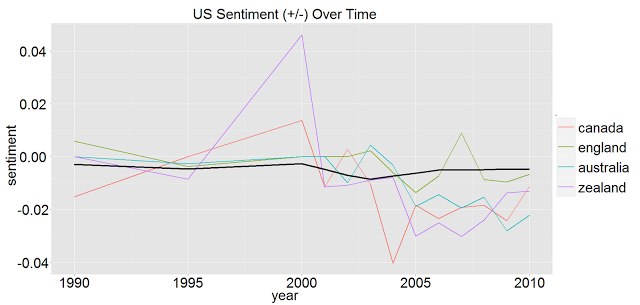 You can see that we seem to have much better sentiment towards the English speaking world, overall.
You can see that we seem to have much better sentiment towards the English speaking world, overall.
Here are US Sentiments towards some of the countries with recent protests/overthrows. Tripoli is a proxy for Libya, and Tunis is a proxy for Tunisia, because those terms did not seem to make it into the JRC-names list that we constructed:
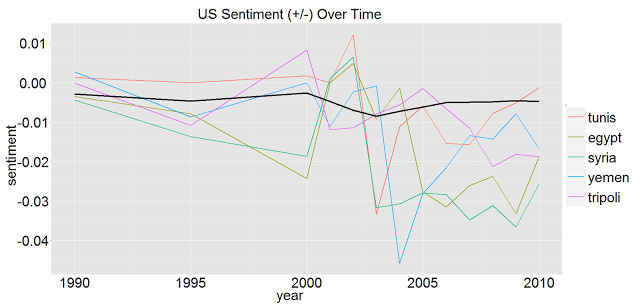
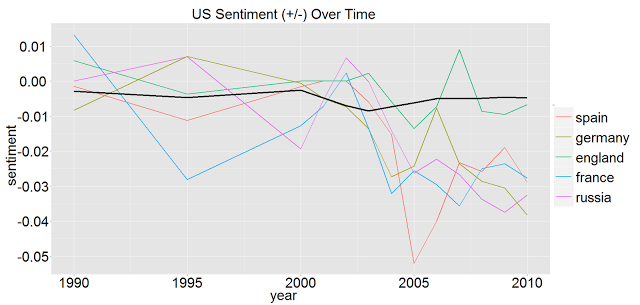
 Country Interpretation
Country Interpretation
The US seems to have slightly negative sentiment towards every country, particularly after 2003. This could be due to many factors:
- Countries not supporting the Iraq war.
- A change from Madeline Albright (1997-2001) to Colin Powell (2001-2005) to Condoleeza Rice (2005-2009). Perhaps their attitudes shaped the attitudes of the cable writers.
- Changes in administration from Bill Clinton (1993-2001) to George Bush (2001-2009) to Barack Obama (2009-). The attitude of the President can definitely impact cable writing, as I can attest, and you can see some upticks in sentiment from 2009-2010, when Obama took office.
Personally, I think that the war may have been the biggest factor in the changing cable language, but this is just speculation, so I would love to hear any ideas on this.
World Figure Plots
Now, we can also plot major world figures:
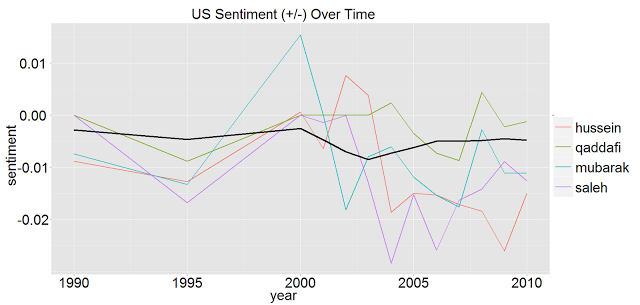 The above are some of the ex-dictators that have been in the news lately. You can see some very interesting patterns (Hussein becomes associated with very negative sentiment right when the second Iraq war starts, for example).
The above are some of the ex-dictators that have been in the news lately. You can see some very interesting patterns (Hussein becomes associated with very negative sentiment right when the second Iraq war starts, for example).
Here are US Sentiments towards some world leaders:
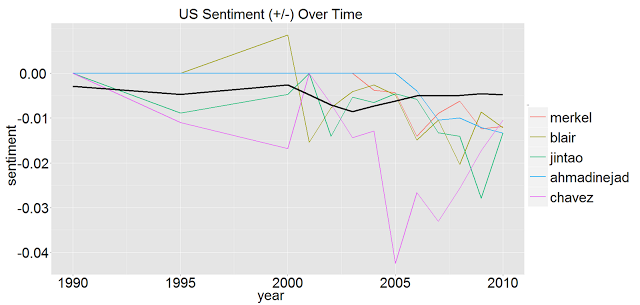 World figure interpretation
World figure interpretation
The US seems to have some strange sentiments towards world figures/leaders.
- The dictators do not seem to have been universally reviled prior to their ousters.
- Sentiment seems to be improving from 2009-2010 (perhaps due to Obama taking office).
Any more interpretation/thoughts would be appreciated!
Conclusion
This has been a very interesting post for me, and I hope that it can be built upon. Please let me know your thoughts, and/or if you would like to see any different analyses done.
